
필자가 처음 제약 업계에서 의료 인공지능 업계로 넘어갔을 때 헷갈리는 용어는 API였다. 제약 회사에서 API는 Active Pharmaceutical Ingredient, 즉 ‘원료 의약품’을 뜻하고, IT업계에서는 Application Program Interface, 즉 ‘서로 다른 소프트웨어 어플리케이션/서비스가 데이터를 주고 받고, 기능을 서로 연결 할 수 있게 해주는 매개체’를 의미한다. 이후 의료 인공지능 업계에서 6년을 일하고 나서, 팔란티어와 같은 플랫폼을 다루는 업계로 넘어가니 이제 다시 헷갈리는 용어가 바로 온콜로지(Oncology)과 온톨로지(Ontology)이다.
‘온콜로지’는 암의 발생 원인, 진단, 치료 및 예방을 연구하는 학문 분야이다. 보통 글로벌 제약사들의 매출에 가장 큰 비중을 차지하는게 항암제이니만큼 제품 파이프라인의 30%이상이 여기에 집중되어 있고, 투자도 많이 되어 있다. 반면에 ‘온톨로지’는 용어 자체가 철학의 존재론에서 유래하였으나, 최근 AI업계 내에서는 ‘특정 도메인 내의 객체(Object), 속성(Property), 관계(Link)를 AI가 이해 할 수 있게 구조화한 지식 모델’이라는 의미로 쓰이고 있다. 한마디로 온톨로지 사용 주체의 ‘도메인 설계도, 도메인 지식 지도’라고 표현 할 수 있다.

온톨로지가 주목을 받기 시작한 것의 중심에는 미국 테크 기업 ‘팔란티어 테크놀로지스(Palantir Technologies)’가 있다. 세간에는 방산기업으로 알려져 있지만, 전체 고객사 수(Installment base) 기준으로 90% 이상은 일반 기업의 운영체제(Enterprise OS) 솔루션인 ‘Foundry’로 구성되어 있다.
기업 내 다양한 데이터 소스를 통합 온톨로지화하고, 그것이 LLM과 결합하면서 기존의 문제점을 해결(할루시네이션 감소, 해당 기업의 맥락이 담긴 도메인 지식 반영, 레퍼런스 추적 가능성 확보 등)한다는 내용이 알려지면서 폭발적인 실적 성장과 주가 상승을 만들어 나가는 중이다.
단, 온톨로지는 팔란티어만의 독자적인 분야는 아니고 과거 시맨틱 웹이나 GraphDB분야에서 사용되던 데이터 모델링 방식이다. 팔란티어가 그것을 자신만의 방식으로 재해석 & 적용하면서 주목 받기 시작한 것일 뿐, 온톨로지 구축은 팔란티어가 아니더라도 할 수 있다.
그렇다면 제약회사의 항암제 R&D 분야에 온톨로지를 어떻게 활용 할 수 있을까? 물질 발굴부터 임상 1~3상까지 다양한 분야에 응용 할 수 있지만, 필자가 추천 하는 분야는 타겟 물질 발굴(Target Discovery)이다. 임상 데이터는 각종 규제와 제약 때문에 첫 도메인으로 무겁고, 타겟 디스커버리는 외부 공개 데이터 비중이 크고, 실패에 대한 기회비용이 크기 때문에 초기 구축 비용 대비 가시적 ROI가 가장 빠르기 때문이다.
현재 제약회사 R&D 현황을 보면 억대 연봉의 연구원들이 연구 대신 구글링 및 문서 작업에 소모하는 시간이 많다. Pubmed, ClinicalTrials.gov, 특허 현황, 경쟁사 임상 파이프라인 검색을 하고 그것을 다시 엑셀이나 PPT 보고서로 만드는데 상당한 시간을 소요한다. 또한 몇 년 전에 A팀이 검토 후 Drop했던 타겟을, B팀이 다시 검토하고 있는 일이 발생 하기도 한다. 더 큰 손실이 날 수 있는 부분은 이미 임상 단계에 들어간 물질에 대한 경쟁사 동일 타겟 임상 정보/임상 실패 정보/특허 정보/유사 기전 독성 시그널 등의 중요 정보가 뒤늦게 발견되어 진행되던 임상 실험의 중단 기회 비용이 커진다는 것이다.
문제는 데이터가 없는 것이 아니다. 데이터는 풍부한데 그것들이 사일로 되어 있고, 암묵지(暗默知)가 형식지(形式知)화 되어 있지 않으며, 각각이 맥락(Context)정보와 함께 연결되지 않아서이다. 단순히 외부 논문, 특허, 임상 정보, 내부 실험 결과를 한곳에 모아두는 것은 평범한 데이터베이스에 불과하다.
하지만 이 데이터들 사이에 ‘어떤 의미로 연관되는지’ 맥락(Context)을 부여하면 살아있는 지식 네트워크인 '온톨로지(Ontology)'가 되는 것이다. 쉽게 말하면 우리 회사 R&D 도메인 지식 지도를 만드는 셈이다. 예를 들어, 특정 '질환 타겟'을 중심으로 “경쟁사의 임상 현황", "관련 특허 만료일", "사내 과거 실패 이력"을 거미줄처럼 엮어내는 방식이다.
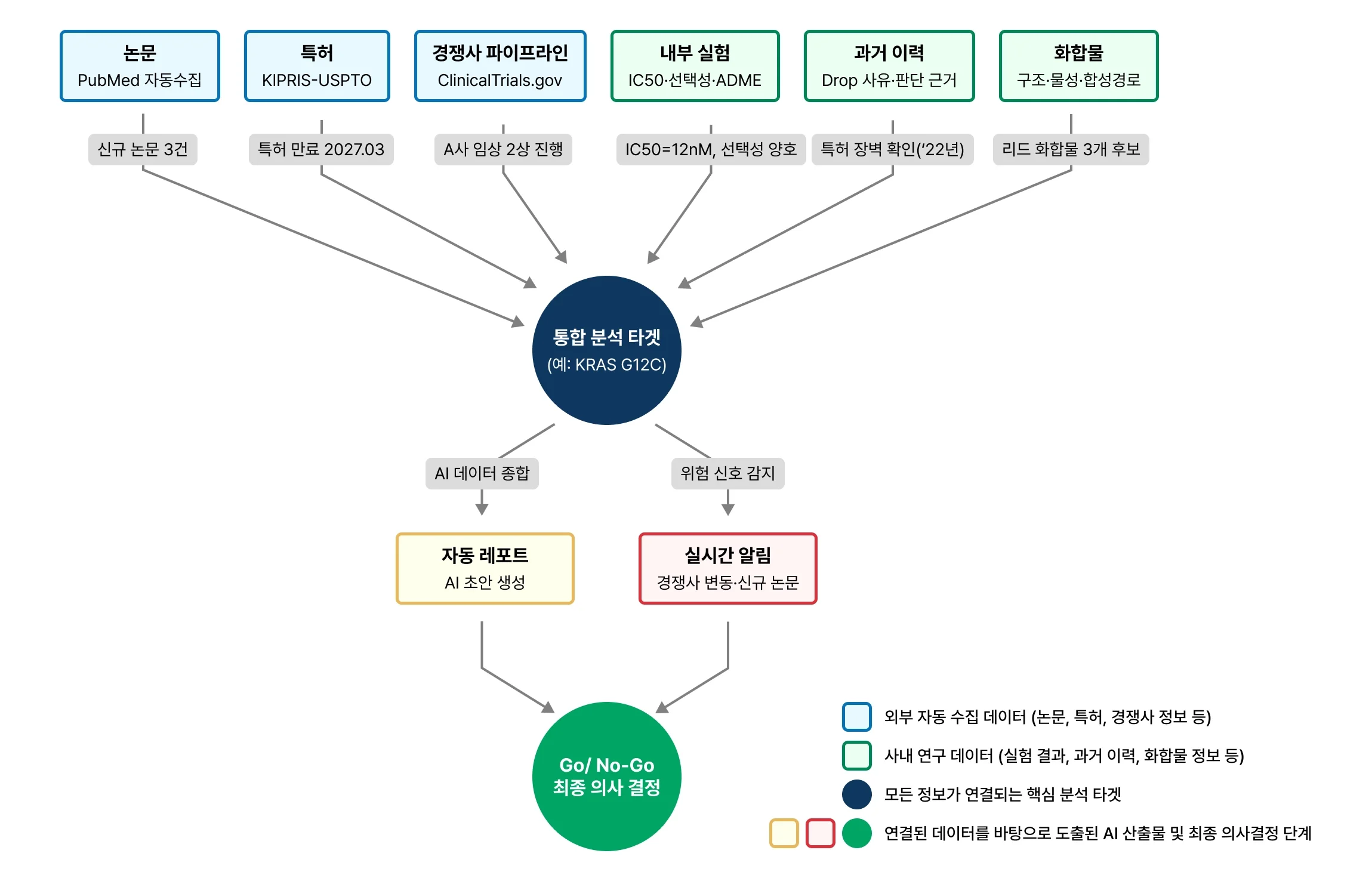
이렇게 하면 데이터가 개별 폴더에 고립되지 않고 서로 꼬리에 꼬리를 무는 관계망을 형성하게 된다. 이처럼 온톨로지로 연결된 데이터는 단순한 정보의 합을 넘어선다. LLM는 부여된 온톨로지 위에서 가동되면서 마치 인간 전문가처럼 흩어진 퍼즐 조각을 맞추고, "경쟁사 진척이 빠르고 특허 장벽이 존재하므로 개발을 중단(No-Go)해야 한다"는 종합적인 통찰을 즉각적으로 도출할 수 있게 된다. 이런 온톨로지화는 R&D와 같은 특정 부분에서 시작되서 다른 분야(임상, 허가, 판매 등)까지 확산 연결 된다는 특성을 가지고 있다. 처음에 구축 단계에 공수가 많이 들어간다는 단점이 있지만 한번 구축해 놓게 되면 유용하게 쓸 수 있다.
신약 개발의 본질은 결국 '시간과의 싸움'이자 '불확실성과의 싸움'이다. 과거에는 더 많은 연구원을 투입해 밤낮없이 논문을 뒤지고 실험 데이터를 엑셀로 정리하는 '양적 팽창'으로 이 싸움을 버텨왔다. 하지만 데이터가 기하급수적으로 폭발하는 AI 시대에는 파편화된 정보를 누가 더 빨리 연결하여 '맥락 있는 통찰'로 바꿔내느냐, 즉 ‘질적 향상’이 기업의 생존을 좌우한다. 위에 언급했듯이 온톨로지 구축은 초기에 도메인 전문가의 지식을 엔지니어와 인터뷰를 통해 코딩(Coding)하고 워크플로우를 연결하는 '한 땀 한 땀'의 고된 인프라 작업이 수반된다. 하지만 이 뼈대가 한번 완성되고 나면, R&D 부서에서 쏘아 올린 작은 데이터가 임상, 인허가, 나아가 상업화 전략까지 유기적으로 연결되는 강력한 전사적 지식 신경망으로 진화하게 된다.
가장 복잡하고 정복하기 어려운 질환인 '온콜로지(Oncology)' 파이프라인의 성공 확률을 높이고 싶은가? 그렇다면 이제 파편화된 데이터베이스를 넘어, 우리 회사만의 고유한 지식 연결 망인 '온톨로지(Ontology)'라는 강력한 무기를 손에 쥐어야 할 때다.